这是一个对于之前介绍的proximal gradient descent,accelerated proximal gradient以及augmented Lagrange multipler算法的实现与对比。
具体的实现代码将会在文章末尾给出。实现的过程虽然说就是照着算法介绍打出来,但是还是有一些感悟的。
- 学习率实际上是非常重要的。之前机器学习课程中,对于学习率只要设一个比较小的值就可以了,而在之前的课程中经过证明(说明),可以知道需要小于$\frac{1}{L}$。我们知道,对于cost function来说,想着重优化哪个term,就需要给它设定更大的权重(比如$\lambda$)。但是在梯度下降以及各个一阶方法中,这个权重重要性主要体现在各个term权重之间的对比,决定了梯度的方向,因此对于过大的权重,要对应较小的学习率(或者进行normalize),否则会让步子迈得太大,得不到更好的优化效果。
- 数学真的很神奇。经过理性分析证明,只需要多几行代码,就可以让收敛率大大提高,大大加速算法。这就是数学的魅力。
这次由于是完成作业,因此使用了不是很熟练的matlab来实现。主要是用这3种算法来恢复稀疏向量,也就是BP(Basic Pursuit)问题。
PGD:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| function [x,difs] = proximal_gradient (x0,A, y,origin)
L =max( eig(A' * A));
lambda = 1;
[m,n] = size(A);
x = x0;
iteration_times = 1000;
i = 1;
w = zeros(n,1);
dif = norm(x - origin,2);
difs = [dif];
while(i<iteration_times)
w = x - 1/L*A' *(A*x - y);
x = soft(w,lambda/L);
dif = norm(x - origin,2);
difs = [difs,dif];
i=i+1;
endwhile
endfunction
|
APG:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| function [x,difs] = accelerated_proximal_gradient (x0,A, y,origin)
L =max( eig(A' * A));
lambda = 1;
[m,n] = size(A);
x = x0;
x_old = x;
x_new = x;
iteration_times = 1000;
p = x;
t = 1;
t_old = t;
beta = t;
i=1;
dif = norm(x-origin , 2);
difs = [dif];
while(i<iteration_times )
t = (1 + sqrt(1 + 4 *t_old*t_old))/2;
beta = (t_old-1)/t;
p = x + beta* (x - x_old);
w = p - 1/L* A' *(A*p - y);
x_new = soft(w,lambda/L);
x_old = x;
x = x_new;
t_old = t;
dif = norm(x -origin,2);
difs = [difs,dif];
i=i+1;
endwhile
endfunction
|
ALM:
需要注意的是这里ALM迭代步骤中有一步是需要用APG(或者PGD)来优化得到最小值。由于这里构造的拉格朗日函数与之前的APG的目标函数还是有一点区别,因此需要重新写个APG函数。
\mathcal{L}_ {\mu}(\boldsymbol{x}, \boldsymbol{\lambda}) \doteq g(\boldsymbol{x})+\langle\boldsymbol{\lambda}, \boldsymbol{A} \boldsymbol{x}-\boldsymbol{y}\rangle+\frac{\mu}{2}|\boldsymbol{A} \boldsymbol{x}-\boldsymbol{y}|_ {2}^{2}
APG_Lagrange:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| function [x] = APG_Lagrange (x0,A, y,mu,lambda,L)
[m,n] = size(A);
x = x0;
x_old = x;
x_new = x;
iteration_times = 10;
p = x;
t = 1;
t_old = t;
beta = t;
i=1;
#dif = norm(x - origin,2);
#difs = [dif]
while(i<iteration_times)
t = (1 + sqrt(1 + 4 *t_old*t_old))/2;
beta = (t_old-1)/t;
p = x + beta *(x - x_old);
w = p - 1/(L*mu) *(mu * A' *(A*p - y) + A' * lambda);
x_new = soft(w,1/(L*mu));
x_old = x;
x = x_new;
#dif = norm(x - origin,2);
#difs = [difs,dif];
t_old = t;
i=i+1;
endwhile
endfunction
|
接下来是ALM,里面用到了上面的函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| function [x,difs] = augmented_lagrange_multipler (x0,A, y,origin)
L =max( eig(A' * A));
beta = 2;
mu = 0.5;
mu_max = 1;
[m,n] = size(A);
lambda = ones(m,1);
x = x0;
iteration_times = 1000;
dif = norm(x - origin,2);
difs = [dif];
i = 1;
while( i<iteration_times )
x = APG_Lagrange(x0,A,y,mu,lambda,L);
lambda = lambda + mu *(A*x - y);
mu = min(beta*mu,mu_max);
dif = norm(x- origin,2);
difs = [difs,dif];
x0 = x;
i=i+1;
endwhile
endfunction
|
可以看到,每个函数主体都不长,而且还包含了我为了可视化因此记录下来每次迭代的error的代码。所以数学真的很神奇。
初次之外,还需要一些别的代码,其中generateXAY用来随机生成$x,A,y$,而soft函数是soft thresholding函数:
1
2
3
4
5
6
7
8
| function [x,A,y] = generateXAY (n,r)
m = 0.5*n;
k = r*n
A = randn(m,n);
x = zeros(n,1);
x(randperm(n,k)) = rand(k,1);
y = A*x;
endfunction
|
1
2
3
| function [ soft_thresh ] = soft( b,lambda )
soft_thresh = sign(b).*max(abs(b) - lambda,0);
endfunction
|
以及main函数,包含了入口以及画图的程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| n = 800;
r = 0.2;
[x,A,y] = generateXAY(n,r);
x0 = rand(n,1);
[x1,difs1] = proximal_gradient(x0,A,y,x);
[x2,difs2] = accelerated_proximal_gradient(x0,A,y,x);
[x3,difs3]= augmented_lagrange_multipler(x0,A,y,x);
err0 = norm(x0 - x,2)
err1 = norm(x1 - x,2)
err2 = norm(x2 - x,2)
err3 = norm(x3 - x,2)
index = 1:1000;
plot(index,difs1,index,difs2,index,difs3);
title(["m=",num2str(n*0.5)," n=",num2str(n)," k=",num2str(r*n)])
xlabel("iteration no.k")
ylabel("l2 error")
legend('PGD','APG','ALM')
|
最后在$m=100,200,400,n=200,400,800$,以及$k=0.1n$的情况下进行了实验,画出了曲线对比图:

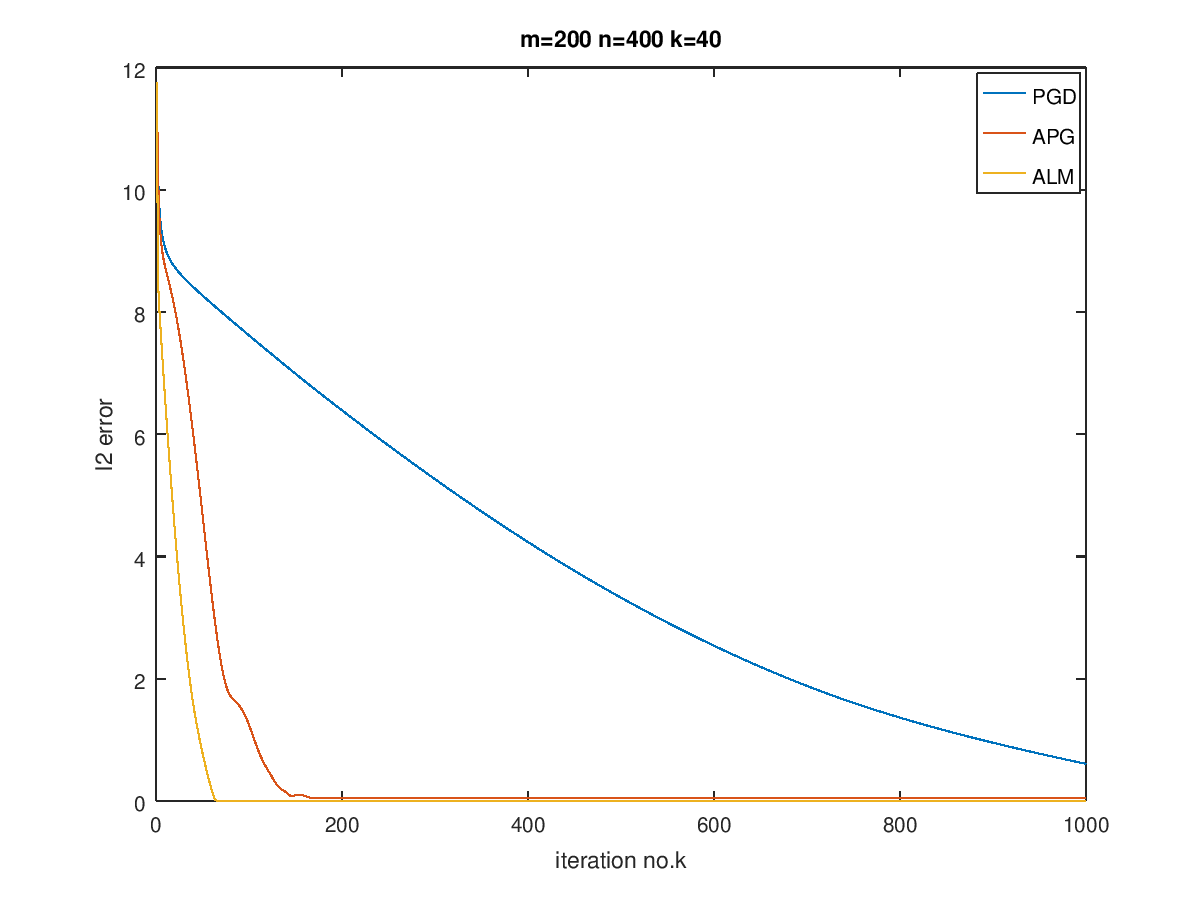
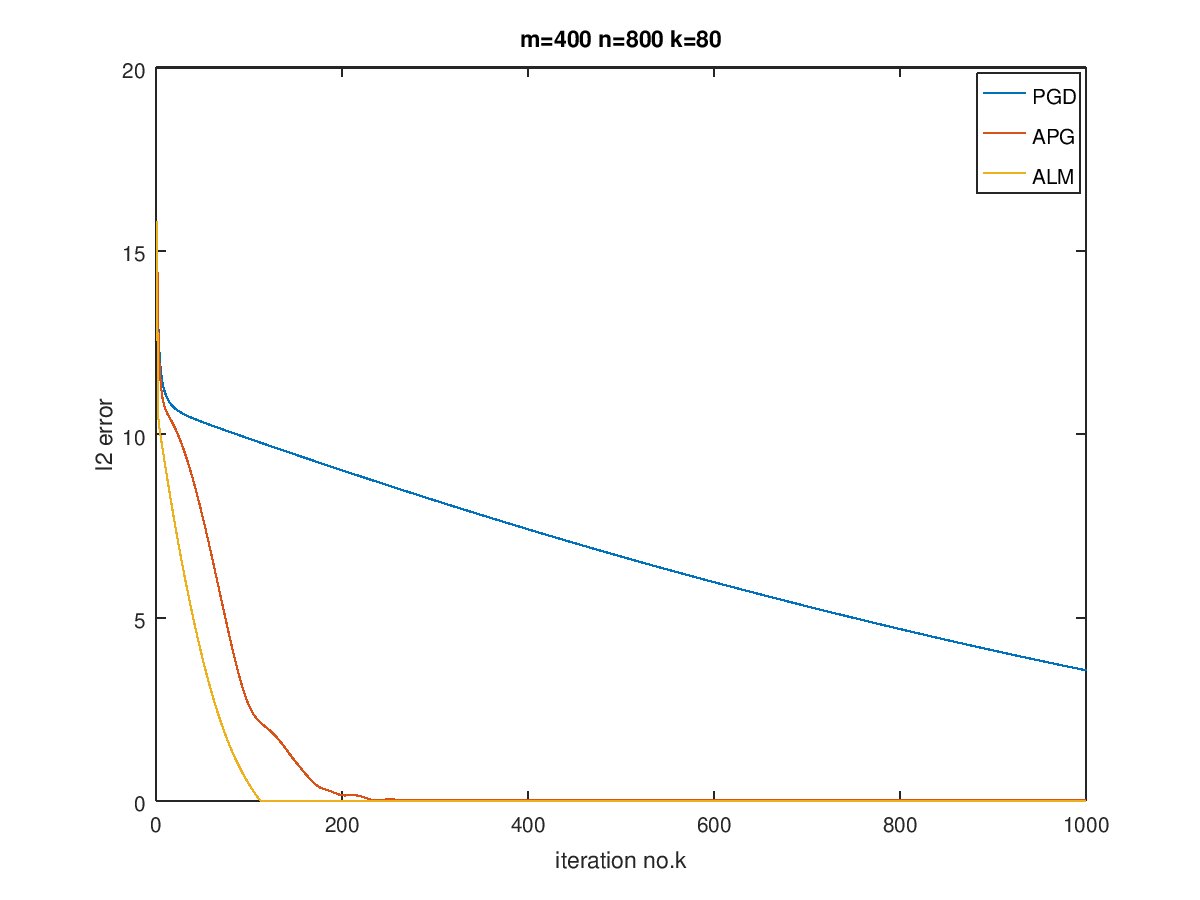
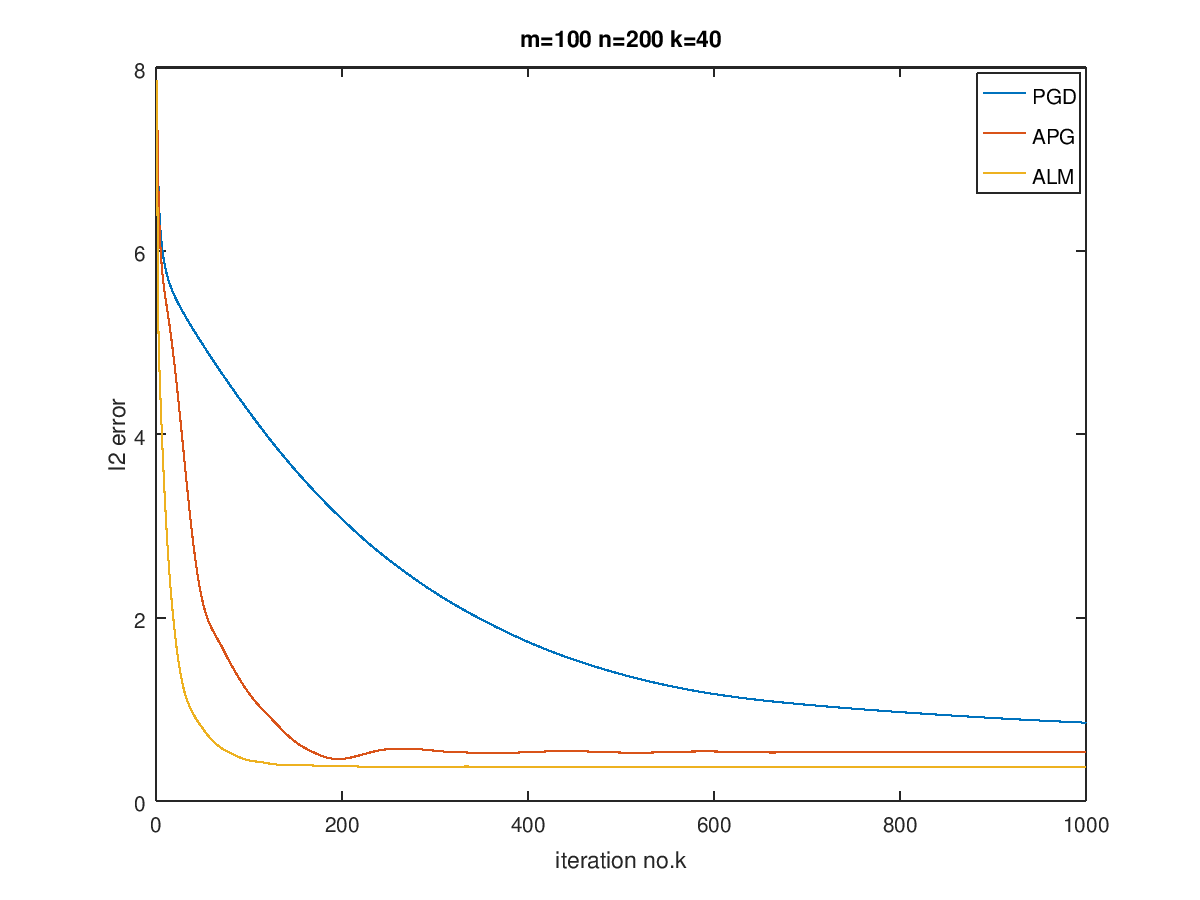
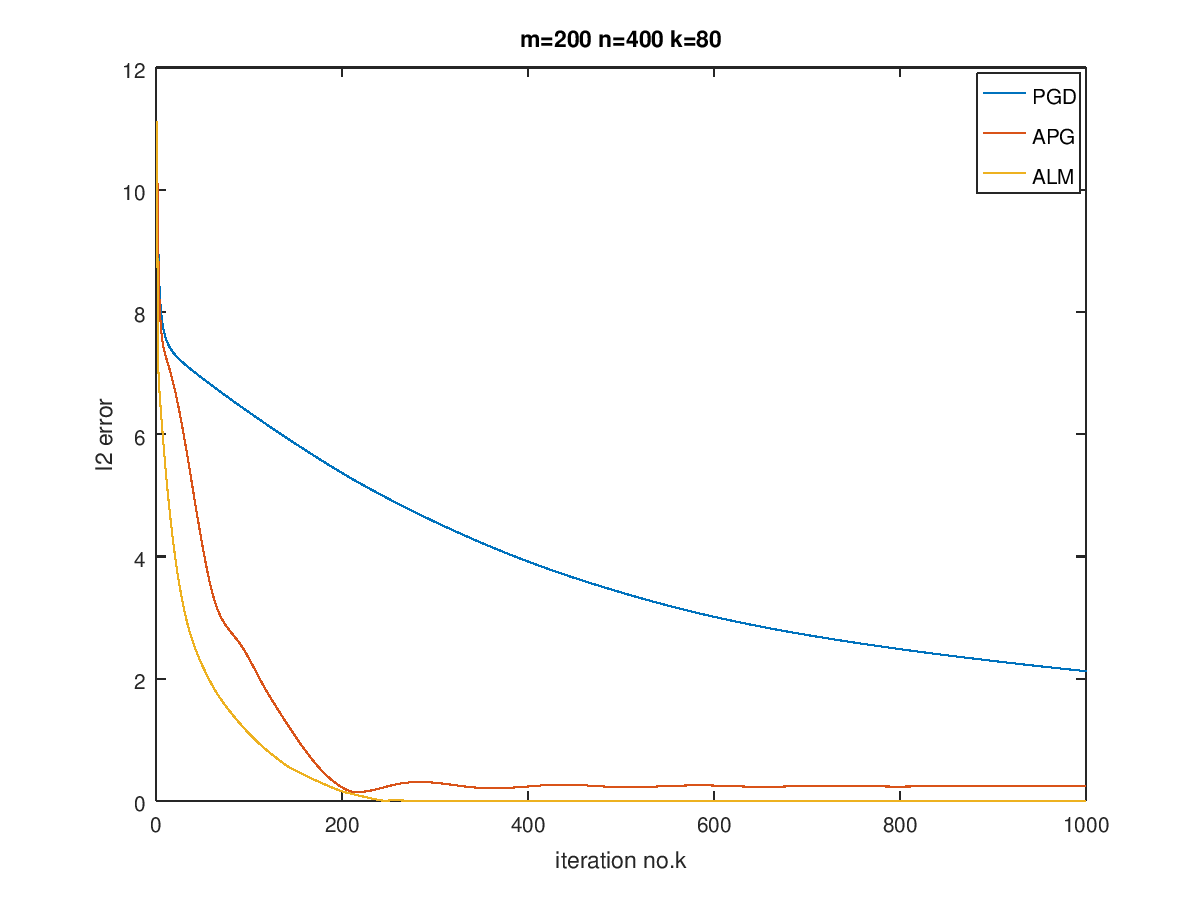
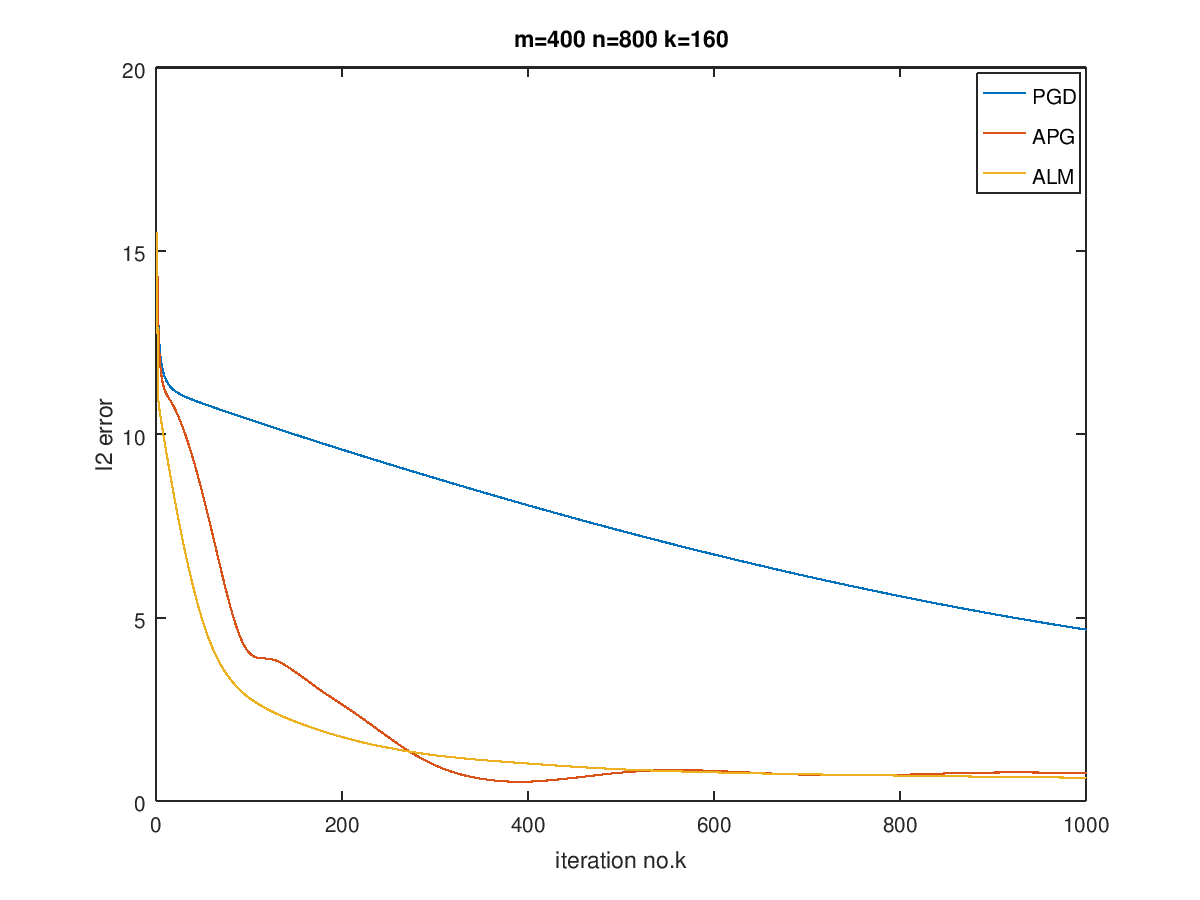
可以看到,对于越稀疏的矩阵,恢复效果越好,而当数据规模增大时,需要更多的迭代次数。
ALM的效果最好,而APG其次,最后是PGD,当然,由于ALM在迭代过程中已经调用了APG算法,因此它与APG迭代一样的次数的话是不公平的,但是总体表现来说还是ALM会更好一点,而且可以看出,收敛后,ALM的error比APG要低。我猜测这是因为ALM就是奔着恢复稀疏矩阵去的,使用了Lagrange构造对偶问题,对单纯的惩罚做法要更好。其他两个算法在有噪声的情况下会更适合,在没有噪声的时候,相比之下会更差一点。